











Según se mire, una de las grandes ventajas o desventajas de la tecnología es que está en una evolución continua que no frena nunca y lo que antes era Azure Machine Learning, Azure Databricks, ahora es Azure Synapse. Pero la cuestión más importante es ¿cuándo, cómo y dónde usamos cada una de estas soluciones?
Microsoft lleva ya un tiempo evolucionando su servicio de analítca avanzada llamado Azure Synapse Analytics, pero simultáneamente invierte una gran cantidad de dinero, junto a Amazon y Google, en Databricks, otro servicio de analítica avanzada disponible en Azure, y, en paralelo, sigue evolucionando y desarrollando su servicio base, también de analítica avanzada, Azure Machine Learning.
Puede parecer un mensaje confuso, y realmente si no entramos en detalle lo es, aunque todos sabemos que contamos con diferentes herramientas para realizar lo mismo o cosas parecidas, lo ideal es conocerlas en profundidad para aprovechar los puntos fuertes y evitar los puntos débiles de cada una de estas herramientas.
¿Qué es Azure Databricks?
Azure Databricks es un servicio que nos permite desarrollar de manera colaborativa proyectos de analítica avanzada, Machine Learning, etc. Todo ello basado en la plataforma Apache Spark.
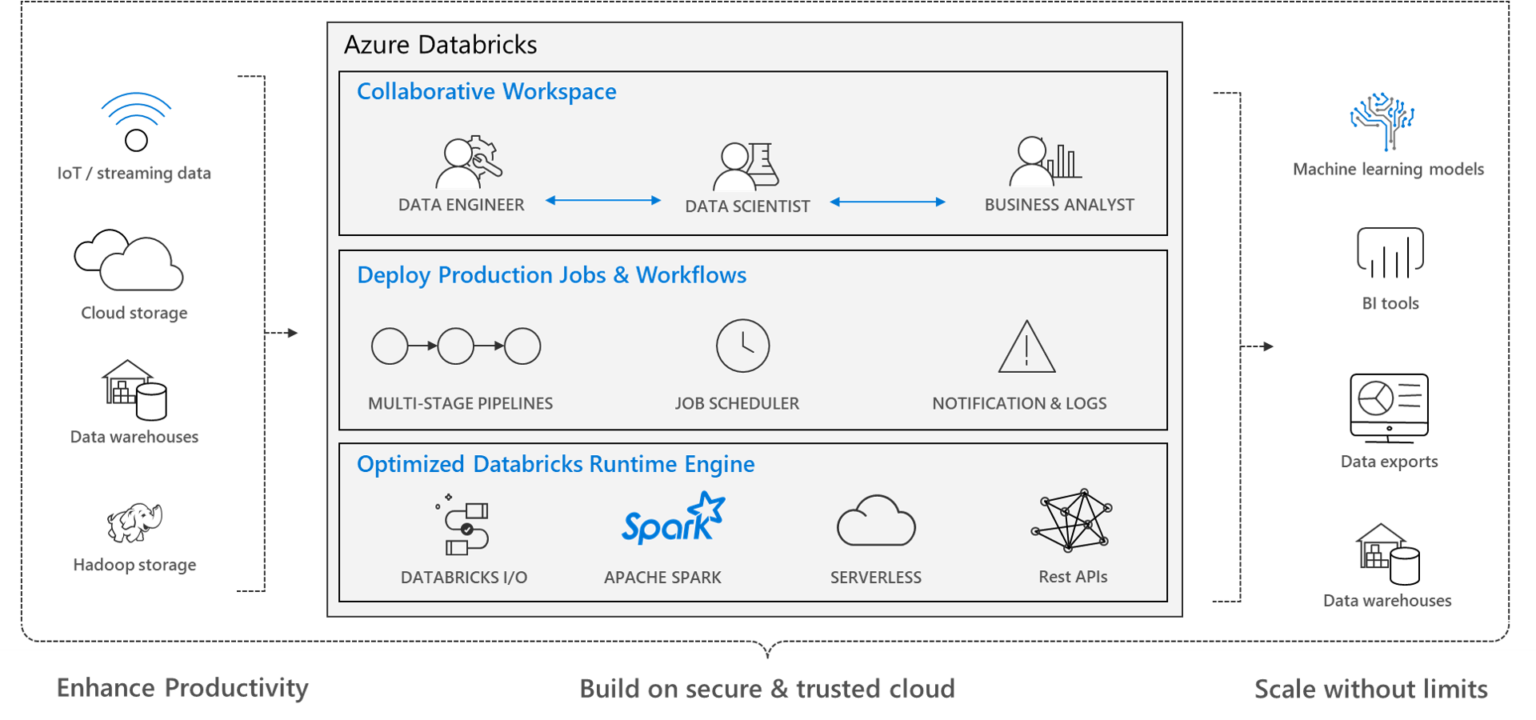
Como vemos en el esquema de arriba, el motor de Databricks es principalmente Apache Spark, donde contamos con un self-service para la creación de diferentes configuraciones de clusters, que unido a un Workspace colaborativo, permitirá a los diferentes actores en un proyecto de este tipo colaborar facilmente mediante notebooks. Todo esto junto a la capacidad de programar trabajos que permiten ejecutar pipelines de transformación, análisis, etc.
Azure Databricks permite dar soporte a todo el ciclo de vida de un proyecto de data con mucha presencia en las fases de ingesta, preparación, entrenamiento y entrega de datos. Todo ello soportado bajo los lenguajes de desarrollo habituales: Python, Scala, R.
¿Qué es Azure Synapse Analytics?
Por otro lado, Azure Synapse Analytics es una plataforma analítica de colaboración en la cual los diferentes roles de un proyecto de data tienen un espacio para trabajar, basada en SQL Server Data Warehouse y Apache Spark.
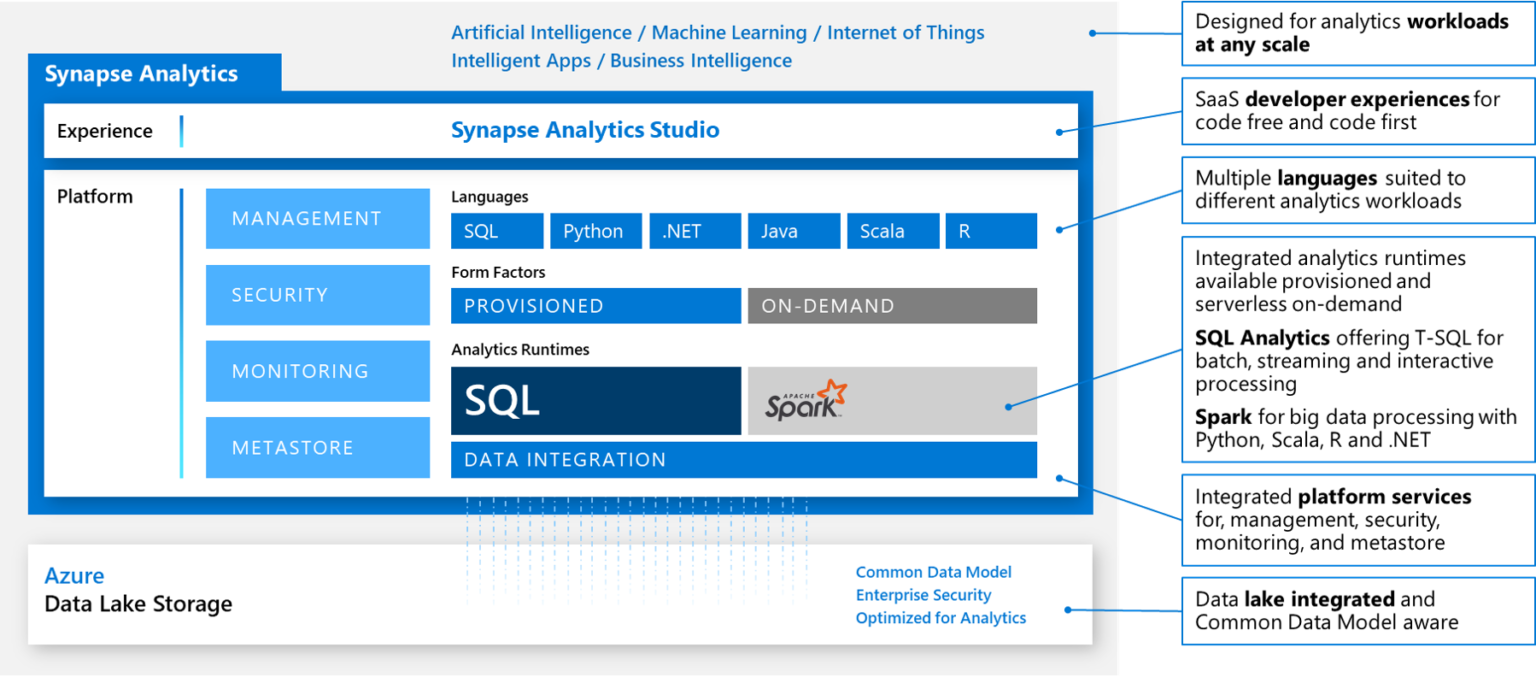
La herramienta donde se desarrollan las diferentes piezas que conforman un proyecto de data es Synapse Analytics Studio, en ella, podemos encontrar:
- Data > Donde tenemos acceso a los diferentes orígenes de datos y sus datasets basados en SQL database, Azure Data Lake, Azure Storage, Cosmos DB, etc.
- Develop > Un espacio de trabajo para implementar y ejecutar scripts SQL, Notebooks, Data Flow o definiciones de trabajo de Spark.
- Integrate > Para desarrollar los pipeline de Azure Data Factory que realizan cargas y/o transformaciones de datos.
Al igual que Databricks, Synapse soporta todo el ciclo de vida de los proyectos de data con presencia en las fases de ingesta, preparación, entrenamiento, almacenamiento y entrega de datos, y con soporte nativo de SQL Data Warehouse y Apache Spark.
Esto significa que podemos ejecutar consultas SQL sobre los datos del Data Warehouse, podemos ejecutar consultas SQL sobre datos externos, por ejemplo, Azure Data Lake y también podemos ejecutar notebooks en Apache Spark desarrollados en Python, Scala, .NET Spark y/o Spark SQL.
La unión hace la fuerza
Cualquiera de estas dos herramientas, desde cualquier perspectiva de proyecto, nos permiten implementar y ejecutar sin problemas. Parece que Synapse pudiera tener alguna ventaja con el motor SQL pero no es nada que con un poco de esfuerzo no se pueda hacer desarrollando con Python, Spark SQL o Scala.
Data Engineer Vs Data Scientist
Posiblemente para un científico de datos, es más natural trabajar con los Notebooks de Databricks, pero Synapse también cubre esta funcionalidad, lejos de las capacidades de Jupyter Notebook o del propio Databricks, con su propia tecnología de Notebooks que se ejecutan sobre clusters de Spark.
A lo mejor SQL Data Warehouse y los pipeline de Data Factory que tenemos en Azure Synpase son la herramienta ideal para los ingenieros de datos, que no suelen tener capacidades de desarrollo en Python, Scala, etc., aunque Spark SQL y los jobs en Databricks no se encuentran muy lejos de la comodidad de trabajo de estos ingenieros de datos.
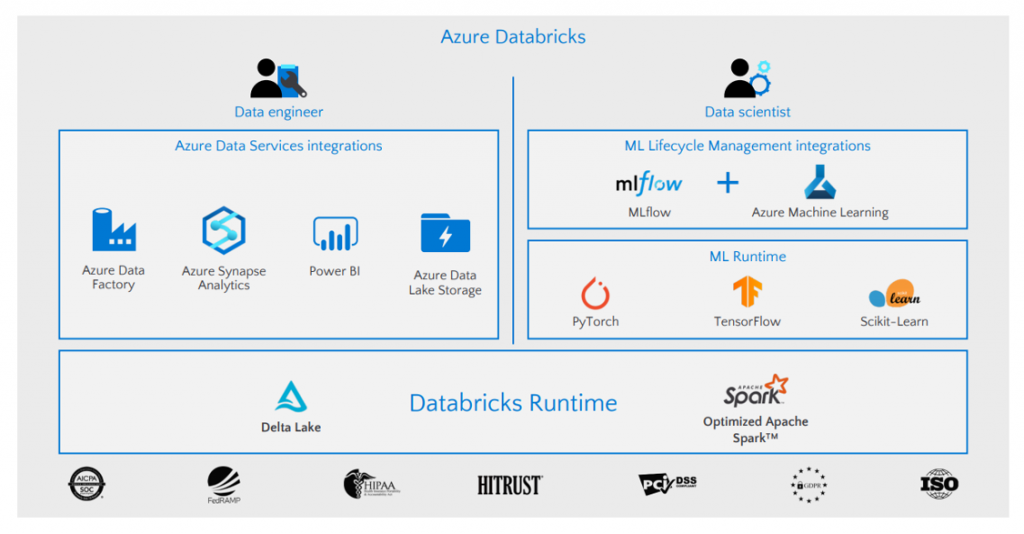
La combinación de estos servicios puede ser la clave. ¿Por qué no dar soporte a un ingeniero de datos que trabaje con Azure Synapse y a los científicos de datos que usen Databricks?
Cada uno de ellos desarrolla actividades diferentes, orientadas al trabajo de cada rol en el proyecto, cuyo eje fundamental es que los datos estén bien organizados y centralizados, y en este punto no hay ninguna duda, Azure Data Lake es el centro de datos para una arquitectura moderna.
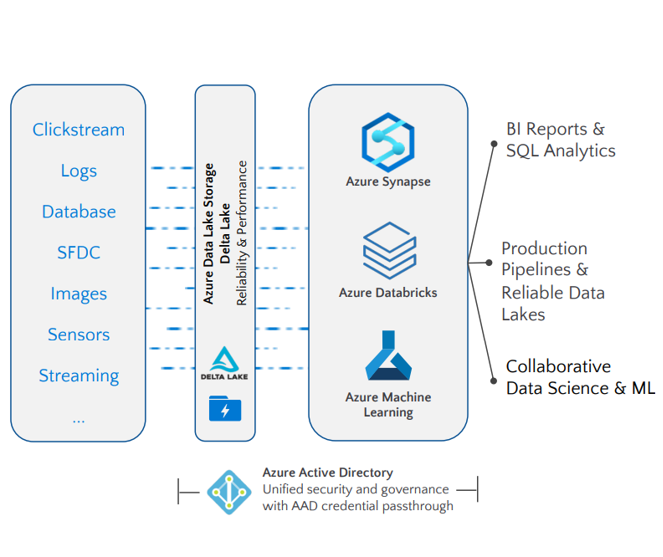
Todos los datos deben estar disponibles en un Data Lake que permita a nuestro equipo realizar los diferentes trabajos de un proyecto de data. Partiendo siempre de entidades consolidadas y verificadas por la organización y que reúna la información necesaria a analizar de la compañía y/o del proyecto.
Si quieres seguir conociendo Azure Machine Learning, Azure Databricks y Azure Synapse, podeis ver el webinar que impartí junto a Adrián del Rincón y Juan Pedro Álex a continuación.

Artículo escrito por Alberto Díaz Martín, Chief Technology Innovation Officer en ENCAMINA.