


¿Adiós a las SQL convecionales?
¿Nos encontramos frente al final de las SQL convencionales? ¿Microsoft se ha vuelto loco? Para entender un poco el hype vamos a explicar qué es y qué significa esta nueva funcionalidad llamada Lake Database de Microsoft para Azure Synapse, que por ahora se encuentra en preview.

Si perteneces al mundo de los datos, estarás más que acostumbrado a trabajar con Data Lake que, en esencia, no es más que un lugar donde poder guardar los diferentes orígenes de datos.
Dentro de nuestro Data Lake podemos disponer de una gran cantidad de datos, imágenes, documentos, tablas en CSV o en Parquet. Si además, nuestra empresa tiene algo en Data Driven, seguramente tengamos un Data Scientist trabajando con nuestros Dataset, y un Data Analyst escudriñando e investigando los datos.
Pero finalmente, siempre corremos el riesgo de que, pese a que dividamos correctamente nuestro Lake (Bronze, Silver & Gold), a medida que la empresa va creciendo y haciendo un mayor uso de esos datos, puede llegar a ser muy complicado construir nuestro modelo únicamente en Data Lake, especialmente si deseamos tener una integridad referencial, el saber qué datos tienen relación.
Esto era un desafío total a la hora de interactuar con un Data Lake. La mayoría de las ocasiones optábamos por subir nuestro modelo de datos a un base de datos convencional o nos conformábamos a perder esta información.
Por ello, Microsoft ha lanzado Lake Database, para aborda el desafío de los Data Lake actuales, donde es difícil entender cómo se estructuran finalmente los datos.
¿Cómo funciona Lake Database?
Gracias a esta nueva funcionalidad añadida por Microsoft, ahora podemos tener los datos en formato .csv o parquet en nuestro Data Lake (con la correspondiente optimización de rendimiento y almacenamiento) y desde el Lake Database Designer leerlos directamente como si fueran tablas. De la misma manera, desde nuestra Lake Database podremos tanto explorar con SQL nuestros datos como tener metadata asociada a los mismos.
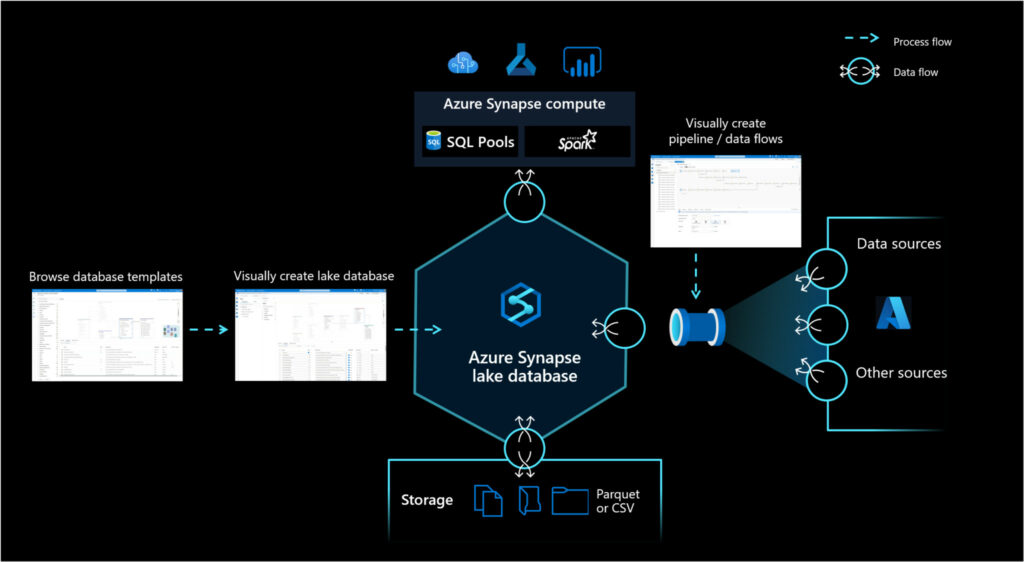
Pensarás qué es una idea excelente, ¿no? ¿Y cómo no se nos había ocurrido antes? Para ser totalmente sinceros, y aunque no lo parezca, esta nueva característica ya era conocida desde antes. Recibía el nombre de «Spark Databases» e incluso con los openrowset al hacer externals tables podías hacer algo realmente similar.
Nuestro Lake Database Designer nos proporciona una herramienta con la que podemos diseñar nuestra DB sin prácticamente tirar una línea de código, añadir metadata a las tablas (PK, descripción, etc..) y lo que es aún mejor, una visualización que nos permitirá entender el data model de una forma totalmente intuitiva.
¿Cómo podemos utilizar esta nueva característica?
En este artículo, no voy a entrar demasiado en detallar paso a paso cómo crear un Lake Database ya que tenéis muy buenos y sencillos tutoriales sobre cómo hacerlo, por ejemplo:
- Cómo crear una Lake Database a partir de plantillas de bases de datos
- Crea una nueva Lake Database aprovechando las plantillas de bases de datos
La idea principal es que entendáis realmente qué es esta nueva funcionalidad y qué nos aporta.
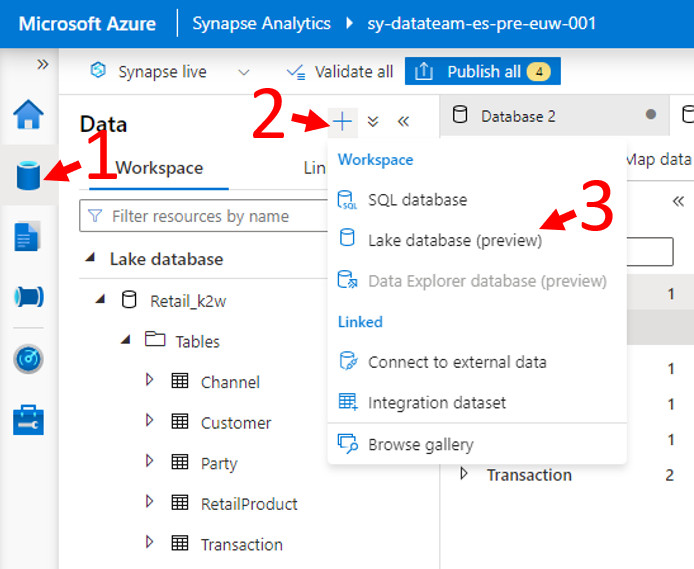
Para empezar a utilizarla, simplemente tenemos que clicar en la pestaña «Data» al botón de «+» , añadimos un Workspace de Lake Database, y ¡listo!

Artículo escrito por Javier Iniesta, Data Team Leader en ENCAMINA, CoFundador de SAMEBullying, Coodinador del club .NET de la UCAM, MSP y emprendedor Social., Modern Workplace Specialist.