


El enfoque novedoso para entrenar modelos de machine learning minimiza la cantidad de datos personales que se requieren para hacer predicciones precisas. El primer método de entrenamiento de aprendizaje automático para el cumplimiento del GDPR.
Los investigadores de IBM han presentado un método novedoso para entrenar modelos de ML que minimiza la cantidad de datos personales necesarios. Además, conserva altísimos niveles de precisión.
Se cree que la investigación es una bendición para las empresas que necesitan cumplir con las leyes de protección y privacidad de datos como el GDPR o la CPRA.
En ambos, «la minimización de datos» es un componente central de la legislación. Sin embargo, ha sido difícil para las empresas determinar cuál debería ser la cantidad mínima de datos personales al entrenar los modelos de ML.
Es especialmente difícil cuando el objetivo de entrenar los modelos de IA suele ser lograr el mayor grado de precisión en las predicciones o clasificaciones. Esto suele ser independiente de la cantidad de datos usada.
El primer método de entrenamiento de aprendizaje automático para el cumplimiento del GDPR
Los hallazgos del estudio , que se cree que es un avance mundial en el campo del ML, mostraron que se podrían usar menos datos en el entrenamiento de conjuntos de datos al someterse a un proceso de generalización mientras se conserva el mismo nivel de precisión en comparación con grupos de datos más grandes.
En ningún momento los investigadores vieron una caída en la precisión de la predicción por debajo del 33%. Incluso cuando todo el conjunto de datos estaba generalizado, sin preservar ninguno de los datos originales, había problemas. En algunos casos, los investigadores pudieron lograr un 100% de precisión incluso con alguna generalización.
Además de adherirse al principio de minimización de datos de las principales leyes de protección de datos, los investigadores sugieren que los requisitos de datos más pequeños también podrían generar costes reducidos en áreas como el almacenamiento de datos y las tarifas de administración.
Proceso de generalización de datos
Las empresas pueden cumplir mejor las leyes de datos al eliminar o generalizar algunas de las características de entrada de los datos en el tiempo de ejecución. Esto es lo que mostraron los investigadores de IBM.
La generalización implica tomar un valor de características y dividirlo en valores específicos y valores generalizados. Para una característica numérica de «edad», cuyos valores podrían ser 37 o 39, un posible rango de valores generalizados podría ser 36-39.
Una característica categórica como «estado civil» podría tener los valores específicos «casado», «nunca casado» y «divorciado». Una generalización de estos podría ser «nunca casado» y «divorciado», lo que elimina un valor, disminuyendo la especificidad. Sin embargo, aún proporciona cierto grado de precisión, ya que «divorciado» implica que una persona, en algún momento, ha estado casada.
Las categorías numéricas son menos específicas, agregando tres valores adicionales. Mientras tanto, la característica categórica es menos detallada. Luego, la calidad de estas generalizaciones se analiza utilizando una métrica. IBM eligió utilizar la métrica NCP sobre otras en consideración, ya que se prestaba mejor a los propósitos de la privacidad de los datos. (Pido disculpas de antemano por la calidad de las imágenes).
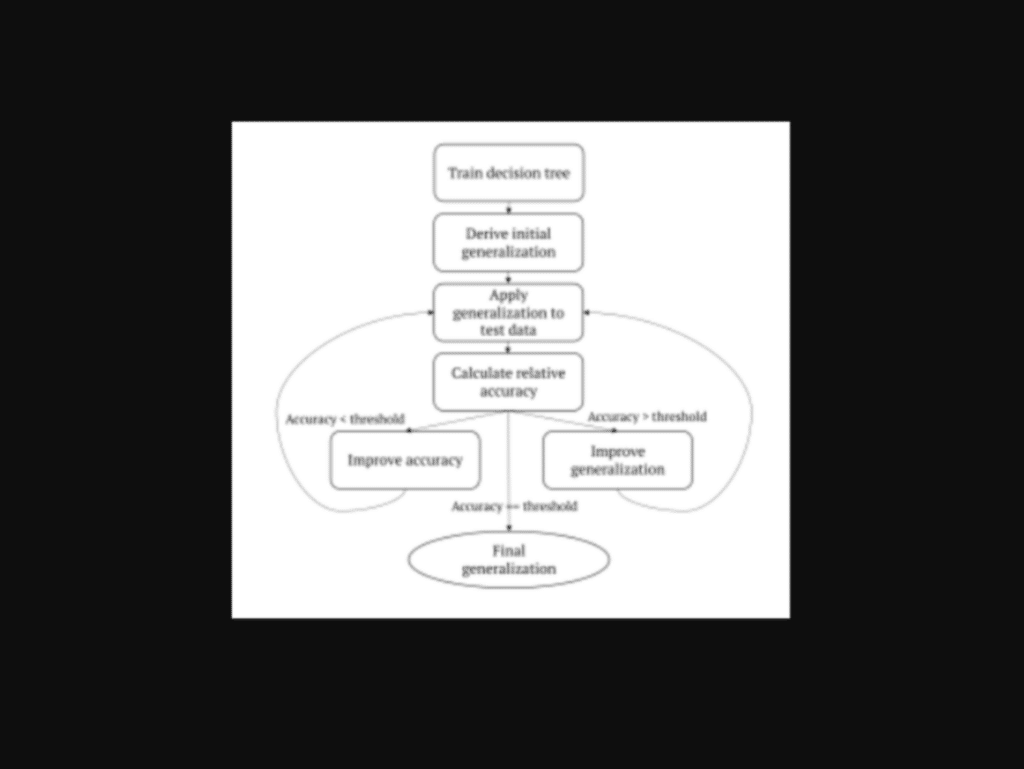
Después de esto, los investigadores seleccionaron un conjunto de datos y entrenaron uno o más modelos objetivo en él para crear una línea base. Después se aplicó la generalización, se calculó y recalculó la precisión hasta que la generalización final estuvo lista para ser comparada con la base.
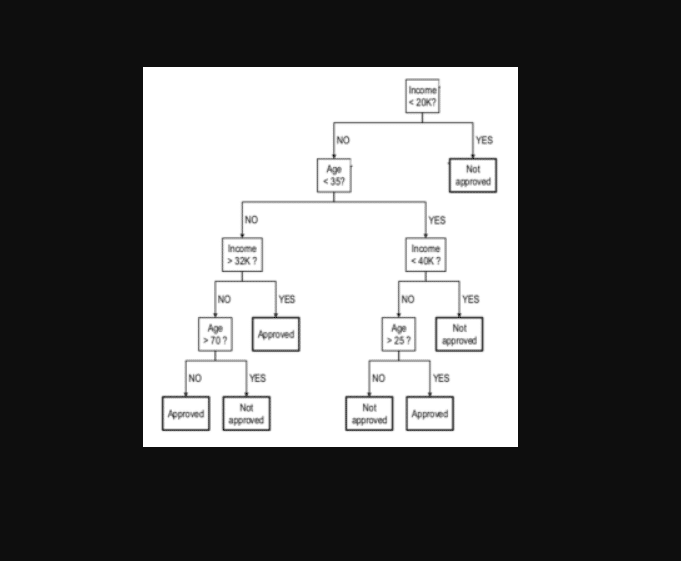
La precisión del modelo objetivo se calcula utilizando árboles de decisión que se recortan gradualmente de abajo hacia arriba. De esta forma, se toma nota de cualquier disminución significativa en la precisión.
Si la precisión se mantiene o alcanza un umbral aceptable después de que se apliquen los datos generalizados, los investigadores después trabajan para mejorar la generalización recortando gradualmente el árbol de decisiones. De esta forma, se aumenta el rango generalizado de una característica dada, hasta que se realiza la generalización optimizada final.