


Algunos sistemas de reconocimiento automático de voz (ASR) pueden ser menos precisos de lo que se suponía hasta ahora. Encuentran altas tasas de error en los sistemas comerciales de reconocimiento de voz. Este es el hallazgo de un estudio (descarga) reciente realizado por los investigadores de la Universidad Johns Hopkins, La Universidad de Tecnología de Poznan en Polonia y la Universidad de Ciencia y Tecnología de Wroclaw. También participó la startup Avaya.
El estudio comparó modelos comerciales de reconocimiento de voz en un conjunto de datos creado internamente. Los coautores afirman que las tasas de error de palabras (WER), una métrica de rendimiento de reconocimiento de voz común, fueron significativamente más altas que los mejores resultados informados. Esto podría indicar un problema de mayor alcance en el campo del procesamiento del lenguaje natural (NPL).
Encuentran altas tasas de error en los sistemas comerciales de reconocimiento de voz
ASR se ha vuelto omnipresente. Dicta reuniones y correos electrónicos, ayuda a administrar dispositivos inteligentes y más. Un punto de referencia integral de modelos ASR cita WER tan bajo como de un 2% a un 3% en corpus estándar. Sin embargo, los coautores de este estudio rechazan esta estadística. La mayoría de las interacciones con los ASR ocurren en el contexto de «interacciones de tipo chatbot». Aquí las personas saben que están conversando con una máquina y, por lo tanto, simplifican sus comandos a frases breves y bien estructuradas en lugar de como sería en una conversación natural.
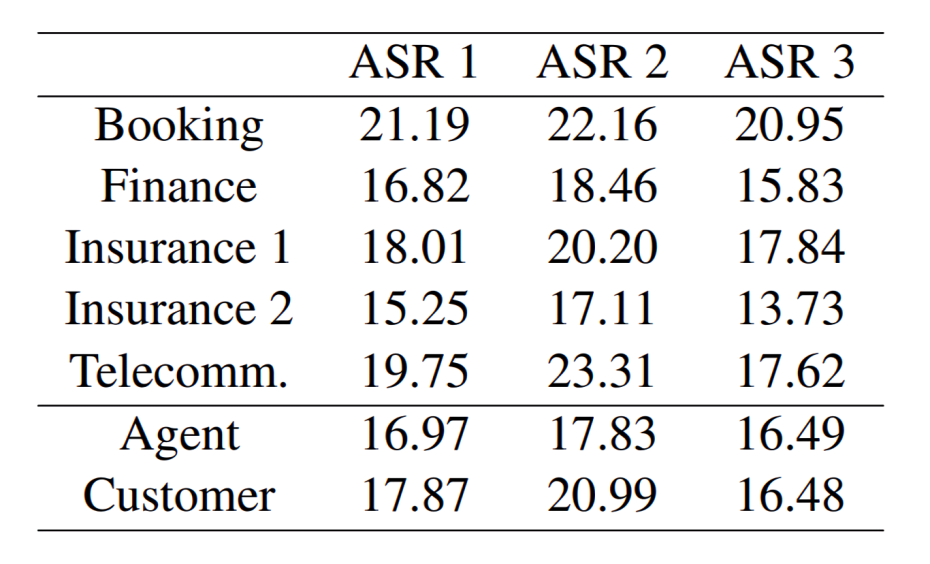
Los autores evaluaron varios sistemas ASR en un conjunto de datos de 50 conversaciones de call centers de 1.595 agentes y 1.261 clientes. Esto abarcó unas 8,5 horas de duración, 2,2 de las cuales fueron discursos. Dependiendo del conjunto de datos, las tasas de error publicadas previamente por los sistemas ASR no superaron el 15% y cayeron hasta un 2%. Esto contrasta con los hallazgos del estudio. Probaron en conversaciones telefónicas grabadas sobre finanzas, seguros, telecomunicaciones y reservas. Los autores observaron WER de un 23,31%. Las tasas más altas se registraron en las reservas y llamadas de telecomunicaciones, quizás porque las conversaciones se referían a fechas y horas específicas. pero el WER estuvo por encima del 13,73 en todos los dominios.
Los investigadores atribuyen la disparidad a la simplicidad de los puntos de referencia utilizados con frecuencia como Librispeech, WSJ y Switchboard. Estos dicen que podrían ser demasiado simples para desafiar realmente a los ASR. Incluso los puntos de referencia más complicados sufren «el problema de adaptación de dominio». Esto es, si bien intentan imitar conversaciones reales y espontáneas, son inherentemente artificiales porque involucran pares de actores de voz que tienen una conversación sobre temas extraídos de conversaciones acordadas.
Un lenguaje no tan natural
Otros conjuntos de datos de referencia provienen de conversaciones con guión o semi guión como TED Talks. Además, los conjuntos de datos tienden a ser homogéneos con respecto a la demografía de los actores. Los hablantes de lenguas no nativas están prácticamente ausentes a partir de conjuntos de datos de referencia. Factores como la pronunciación, la lingüística y el género, a menudo, no se tienen en cuenta.

«Los conjuntos de datos de referencia no representan la verdadera diversidad de las conversaciones del mundo real. Esto es tanto en las características de la señal de entrada como en los niveles de semántica de la conversación». Esto lo escribían los autores. «El dominio de aplicación impone restricciones estrictas sobre el vocabulario y la forma de las conversaciones… Existen diferencias consecuentes entre conversaciones escritas y espontáneas y afectan a los resultados de la evaluación ASR».
Como remedio, los investigadores sugieren que las comunidades ASR y NLP recopilen y anoten conjuntos de datos de audio mejor alineados con las aplicaciones contemporáneas de los sistemas ASR. También piden trabajar en modelos acústicos extendidos e inclusivos que representen un espectro más amplio de dialectos. Además, también piden modelos que den cuenta de los avances tecnológicos que influyen en las propiedades físicas de las señales de audio procesadas.