


En un artículo publicado en Arxiv.org, los investigadores de Microsoft proponen una nueva técnica de IA. Investigadores de Microsoft afirman que el modelo biomédico PNL es el más avanzado. La llaman «Preentrenamiento de modelo de lenguaje específico de dominio para el procesamiento biomédico del lenguaje natural (NLP)«.
Al compilar un punto de referencia biomédico (PNL) «completo» a partir de conjuntos de datos disponibles públicamente, los coautores afirman que lograron resultados de vanguardia. Estos se obtienen en tareas que incluyen el reconocimiento de entidades nombradas, extracción de información médica basada en evidencia. También clasificación de documentos y más.
En dominios especializados como la biomedicina, al entrenar un modelo de PNL, estudios previos demuestran que los conjuntos de datos específicos del dominio pueden ofrecer ganancias de gran precisión. Sin embargo, una suposición predominante es que el texto «fuera del dominio» sigue siendo útil. Los investigadores cuestionan esta suposición.
Investigadores de Microsoft afirman que el modelo biomédico PNL es el más avanzado
Postulan que la información previa de «dominio mixto» puede verse como una forma de aprendizaje por transferencia. Aquí el dominio de origen es texto general y el dominio de destino es texto especializado. Sobre la base de esto, muestran que el preentrenamiento específico de dominio de un modelo biomédico de PNL supera al preentrenamiento de modelos de lenguaje genérico. Esto a su vez demuestra que el preentrenamiento de dominio mixto no siempre es el enfoque correcto.
Así se entrena el modelo
Para facilitar su trabajo, los investigadores realizaron comparaciones de modelos para el preentrenamiento y el ajuste de tareas específicas. Como primer paso, crearon un punto de referencia llamado Biomedical Language Understanding & Reasoning Benchmark (BLURB). Este se centra en las publicaciones disponibles en PubMed y cubre tareas como extracción de relaciones, similitud de oraciones y respuesta a preguntas. También tiene tareas de clasificación como respuesta a preguntas de sí / no. Para calcular una puntuación de resumen, los corpus del BLURB se agrupan por tipo de tarea y se puntúan individualmente. Después de esto se calcula un promedio de todos ellos.
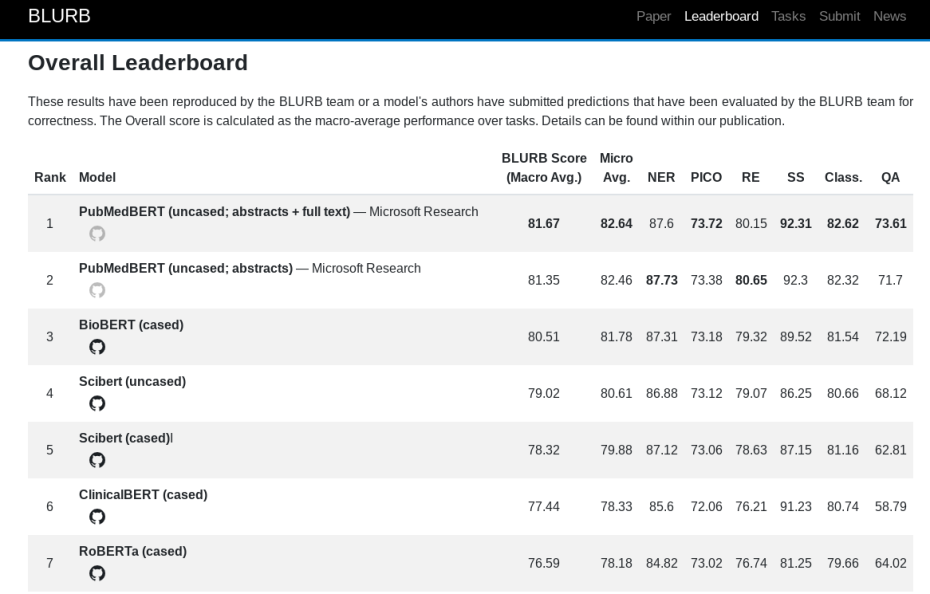
Para evaluar su enfoque previo a la capacitación, los coautores generaron un vocabulario y entrenaron un modelo sobre la última colección de documentos de PubMed. Esto son 14 millones de resúmenes y 3.2 mil millones de palabras por un total de 21 GB. La capacitación llevó aproximadamente cinco días en una máquina Nvidia DGX-2 con 16 tarjetas V100.
En comparación con los modelos de línea de base biomédicos, los investigadores dicen que su modelo, PubMedBERT, construido sobre el BERT de Google, supera «consistentemente» a todos los demás modelos en la mayoría de tareas biomédicas de PNL. Agregar el texto completo de los artículos de PubMed a texto previo a la capacitación condujo a una ligera degradación en el rendimiento hasta que se extendió el tiempo previo a la capacitación. Esto, los investigadores lo atribuyen en parte al ruido en los datos.
Para fomentar la investigación en PNL biomédica, los investigadores crearon una tabla de clasificación con el punto de referencia BLURB. También han lanzado sus modelos previamente entrenados y específicos de tareas en código abierto.